説明 + 信頼感
予測やレコメンド、その他のAIの出力をユーザーに説明することは、信頼を築くために不可欠です。この章の内容は次のとおりです。
- ユーザーはAIシステムをどのくらい信頼すべきですか?
- AIが立てた予測の理由がわからないときはどうすればいいですか?
- AIが立てた予測の確信度をユーザーにどのように見せるべきですか?
議論を円滑にし、イテレーションをスピードアップし、落とし穴を避けたいですか? ワークシートを使用してください。
AIを使うときに新しいこと
AIシステムは確率と不確実性にもとづいているため、正しい粒度で説明をすることは、システムがどのように動くのかをユーザーが理解するのにつながります。ユーザーは、システムの能力と限界についての明確なメンタルモデルをもったら、目的を達成するためには、システムをいつどのように信頼すればいいかを理解することができます。つまり、説明と信頼感は、本質的にひとつづきのものです。
この章では、AIが何をしていて、どのデータを意思決定に使っていて、モデルの出力の「確信度」について、いつどのように説明するか、考えるべき点を説明します。
AIシステムを説明するための、主な考えるべき点は次のものです。
➀ ユーザーが自分の信頼感を調整できるようにする。AIプロダクトは統計と確率にもとづいているため、ユーザーは、システムを完全に信頼するべきではありません。そうではなく、システムの説明にもとづいて、ユーザーはいつシステムの予測を信頼し、いつ自分の判断をするかを知っておくべきです。
➁ 理解のために最適化する。ときには、複雑なアルゴリズムの出力について、明確で包括的な説明がないときがあります。AIの開発者でさえ、それがどのように動いているのか、正確にはわからないこともあります。他のケースでは、予測の背後にある推論は知っていますが、ユーザーがわかるように説明するのが難しいこともあります。
➂ ユーザーの意思決定への影響を管理する。AIシステムは、ユーザーに何か対応を求める出力をすることがよくあります。システムが「確信度」を、いつ、どのように計算して表示するかは、ユーザーに意思決定すべきときを知らせ、信頼感を調整するうえで重要です。
➀ ユーザーが自分の信頼感を調整できるようにする。
ユーザーは、あらゆる状況で盲目的にAIシステムを信頼するようなことはすべきではありません。そうではなく、信頼感を正しく調整してください。人々がソフトウェアシステムに疑いを抱く「アルゴリズム嫌悪」について、多くの研究例があります。また研究者たちは、AIシステムができもしないことをできると、過度に信頼しているケースも見つけています。システムができることとできないことについて、ユーザーが適切なレベルの信頼感を持つことが理想です。
たとえば、予測が誤っている可能性があることを示せば、ユーザーのその予測への信頼感が低くなります。しかし、長期的に見ると、ユーザーがシステムを過信して失望することがなくなるので、ユーザーはそのプロダクトや企業をもっと使ったり頼りにするようになるでしょう。
データソースを明らかにする
AIのすべての予測はデータにもとづいているため、データソースについても説明をする必要があります。ただし、AIで使うデータソースには、収集や通信をするための法的、公正、または倫理的な考慮事項があるときがあります。「データ収集 + 評価」の章で詳しく説明しています。
ユーザーは、新しいコンテキストで情報を見たとき、自分の情報に驚くことがあります。これは、非公開のはずのデータが公開されているように感じられたり、システムがアクセスしていると思っていなかったデータがあると感じたときに、よく起こります。いずれも、信頼感を損ねるものです。これを避けるために、データがどこから来て、AIシステムがどのようにそれを使っているのかを、ユーザーに説明してください。
同じように重要なことは、モデルが使用しているデータをユーザーに伝えておくことで、システムに重要な情報が欠けていたときに、それを知ることができます。この知識は、ユーザーが特定の状況でシステムを過度に信頼しないようにするのに役立ちます。
たとえば、AIによるナビゲーションアプリをインストールしているときに、ナビゲーションアプリがカレンダーアプリのデータへアクセスするという利用規約に同意したとします。その後、ナビゲーションアプリは、予定に間に合うように、5分後に家を出るようにアラートしました。ナビゲーションアプリからカレンダーの情報へのアクセスを許可したことを、あなたが読んでいなかったり、気がついていなかったり、覚えていなかったら、とてもびっくりすることでしょう。
アプリの機能についての信頼感は、それがどのように動いてほしいか、このようなアラートがどのように説明されているか、についての期待値によります。たとえば、アプリのデータソースに疑いを抱くことがあります。または、スケジュール情報すべてに完全にアクセスできる、という過信をするかもしれません。いずれの結果も、正しいレベルの信頼感ではありません。これを回避するひとつの方法は、通知のなかで、接続されているデータソース(ナビゲーションアプリがどうしてカレンダーについて知っているか)を説明し、そのようなデータ共有を、今後は拒否する選択肢を用意することです。実際に、一部の国の規制では、そのような具体的な状況説明とデータ管理が求められることがあります。
キーコンセプト
できるかぎり、AIシステムは、データの使用について、以下の点を説明する必要があります。
- 範囲。ユーザー個人について収集されているデータの概要と、そのデータのどの面がどの目的に使われているか、わかるようにします。
- 影響。システムが、ひとりのユーザーまたはひとつのデバイスにパーソナライズされているのか、それともすべてのユーザーにむけて集約されたデータを使っているのか、説明します。
- 削除。使われているデータを削除やリセットができるかどうか、ユーザーに伝えます。
この項の考え方で、ワークシートの演習1をやってみましょう。
ユーザーのアクションにあわせて説明をする
自分の行動にすぐに反応が返ってくると、人々はより早く学ぶことができます。それは原因と結果がわかりやすいからです。つまり、説明を出す最適なタイミングは、ユーザーのアクションがあったときだということです。もしユーザーがアクションしてもAIシステムが応答しないときや、予期しない応答をしたときに、説明があれば、ユーザーの信頼を築いたり回復するのに、大いに役立ちます。一方、システムが正常に機能しているときは、ユーザーのアクションに反応することで、ユーザーのシステムへの信頼感を保ち続けることができます。
たとえば、あるユーザーがAIによるレストラン予約アプリの「おすすめ」セクションをタップしたとします。しかし出てきたのは、めったに行くことのないイタリアンレストランのレコメンドばかりだったので、彼らは少しがっかりして、アプリの、関連性のある、パーソナライズされたレコメンドをしてくれることへの信頼感は低くなりました。しかし、もしアプリのレコメンド内に、システムは現在地から1ブロック内のレストランのみをレコメンドするという説明があり、ユーザーがニューヨークのリトル・イタリー(イタリア街)の中心にいたのであれば、信頼感は維持されたでしょう。ユーザーは、自分のアクション(このケースでは特定の場所でのレコメンドを求めること)がシステムにどのような影響を与えるかわかります。
長所と短所を明らかにした双方向のインタラクションを通じて、人が人との信頼を築くように、ユーザーとAIシステムの関係も同じように育つのです。
説明のタイミングをユーザーの操作に直接にあわせることができないときは、説明を表示するのにマルチモーダルデザインを使う方法があります。たとえば、ユーザーがビジュアルインターフェイスと音声インターフェイスの両方でアシスタントアプリを使用しているとき、説明を音声出力には含めずに、ビジュアルインターフェイスに含めて、ユーザーが時間があるときに確認できるようにすることができます。
状況による利害の説明
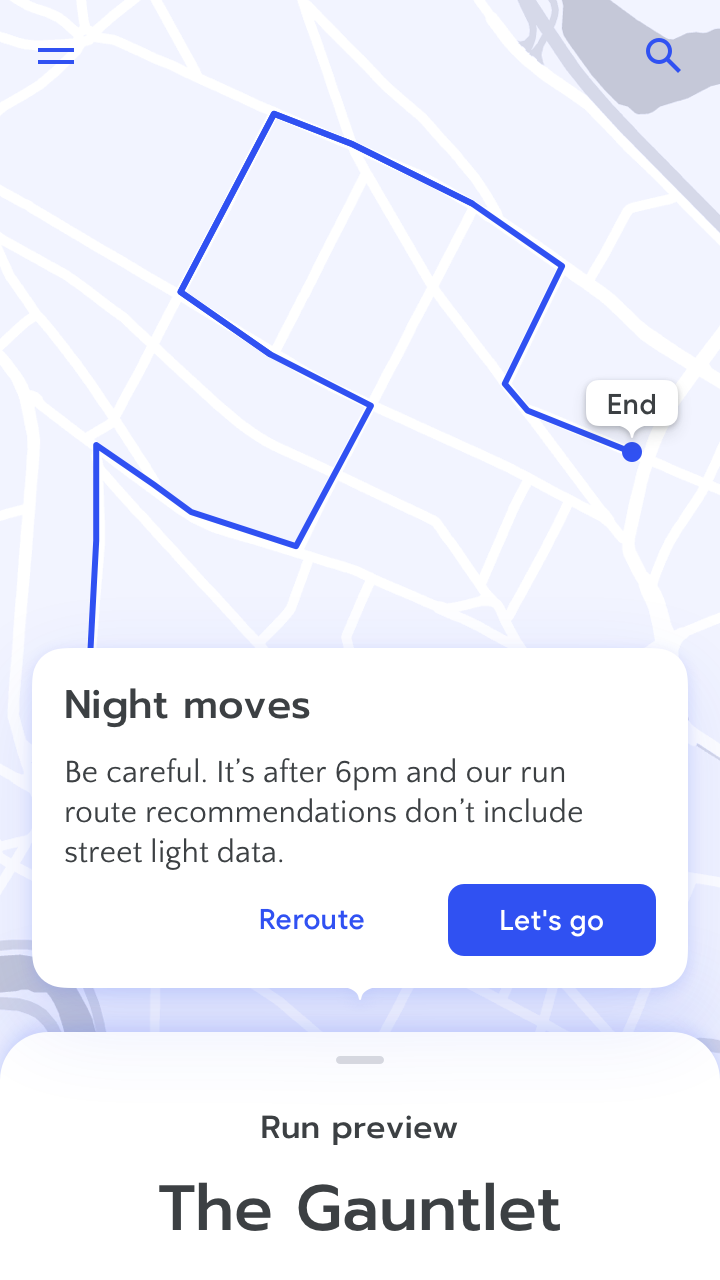
状況や潜在的な影響に応じて、ユーザーに、出力をもっと信頼するように、あるいはあまり信頼しないよう促すよう、説明を使うことができます。「偽陽性」や「偽陰性」、または一定の割合だけずれている予測を、ユーザーが信じてしまうリスクを考えることが重要です。
たとえば、AIによるナビゲーションアプリにおいて、日々の通勤の到着時間の計算方法を説明する必要はないかもしれません。しかし、ユーザーがフライトに間に合うようにとしているときは(通勤よりも利害が大きく、頻度は低い)、レコメンドするルートの到着時間をダブルチェックする必要があるかもしれません。そのようなとき、システムは制限の説明を出して、それを促すようにします。たとえば、ユーザーが目的地として地元の空港を指定したときは、交通量のデータは1時間おきに更新されるだけであることを知らせます。
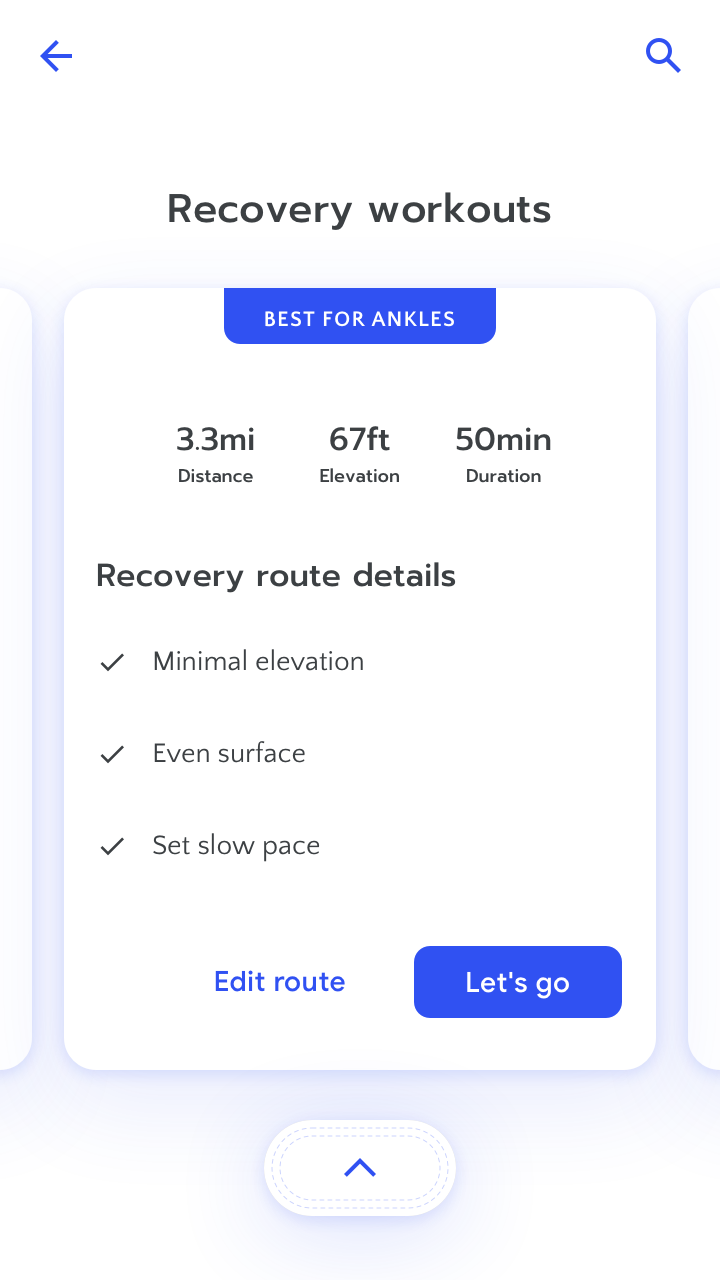
失敗した状況や、予測の確信度が低い状況で、ユーザーに適切なガイダンスをする方法の詳細は「エラー + 上手な失敗」の章にあります。
キーコンセプト
チームで、どんな種類のインタラクションや、結果や、それに対応した説明が、AIシステムへの信頼感を低下させたり、維持させたり、高めたりするか、ブレインストーミングします。これらは「信頼しない」から「信頼しすぎ」までのあいだに分布しているでしょう。
ランニングアプリの例をいくつか挙げます。
- 一度に3マイル以上を走ったことがないユーザーは、マラソントレーニングシリーズのレコメンドを受けます。
- ユーザーがトレーニングのレコメンドをパーソナルトレーナーに見せて、トレーナーがアプリのレコメンドに同意します。
- ユーザーは、リハビリテーションのランニングについてアプリのレコメンドに従いますが、完了するのは困難です。
この項の考え方で、ワークシートの演習2をやってみましょう。
➁ 理解のために最適化する。
上に述べたように、説明は、適切な信頼感を築くために極めて重要です。しかし、AIシステムの説明をすること自体が難しいときがあります。
往々にして、AIの予測の背後にある理論的根拠は不明か複雑すぎて、限られた技術的知識のユーザーが読んでわかるようなシンプルな文に要約することができません。そのため、多くのケースでの最善のアプローチは、すべてを説明しようとすることではなく、ユーザーの信頼感と意思決定に影響を与える面だけを説明することです。
重要なことを説明する
「部分的説明」では、システムが動く仕組みの重要な要素を明らかにしたり、特定の予測に使われるデータソースのうちのいくつかを公開したりします。部分的説明では、システム機能のうち未知の部分や、非常に複雑な部分や、たんに役に立たない部分を、意図的に省略します。好奇心の強いユーザーにもっと詳細を提供するために、「段階的な開示」を部分的説明と一緒に使うこともできます。
AIによる植物分類アプリにおける、「部分的説明」の例を以下に示します。
システムを説明する、出力を説明する
「システム全体の説明」では、特定の入力にかかわらず、システム全体がどう動いているかを説明します。使われるデータの種類、システムが何に最適化しているか、システムがどのようにトレーニングされたか、説明することができます。
「特定の出力の説明」では、特定のユーザーに特定の出力をした背景にある理論的根拠、たとえばある植物の写真がポイズンオークであると予測した理由を、説明します。出力の説明は、説明をアクションに直接に結びつけることができ、ユーザーの作業のコンテキストにおける混乱を解決するのに有用です。
データソース
「回帰」のようなシンプルなモデルは、比較的、どのデータソースがシステム出力にもっとも大きな影響を与えたか明らかにすることができます。複雑なモデルにおいて、影響力のあるデータソースを特定することは、今も活発な研究中の分野ではありますが、時にはできることもあります。できたときには、影響力のある「特徴量」をシンプルな文章やイラストでユーザーに説明することができるでしょう。データソースを説明するもう1つの方法は、「起きなかったもの」を説明することです。これは、AIが特定の決定や予測をしなかった理由を、ユーザーに伝えます。
特定の出力
「この植物はおそらくポイズンオークです。XYZの特徴量を持っていますが、ABCの特徴量を持っていないからです」
「この樹木分布ガイドは、あなたが北米におけるカエデやカシの木の写真をたくさん登録してくれたから、作成されたものです」
システム全体
「このアプリは、色、葉の形、その他の要素を使って、植物を識別します」
モデルの確信度を表示する
AIがその意思決定になぜどのように至ったのかを説明するかわりに、「モデルの確信度」の表示では、AIのその予測がどのくらい確かであるかを説明し、そして可能性のある他の選択肢を表示します。ほとんどのモデルは「N-Best分類」と確信度を出力できるので、モデルの確信度の表示は多くの場合、すぐに利用できる説明方法です。
特定の出力
N-Best分類
もっとも可能性の高い植物:
- ポイズンオーク
- カエデの葉
- ブラックベリーの葉
確信度
予測:ポイズンオーク(80%)
システム全体
確信度
このアプリは、平均80%の確信度で画像を分類します。
確信度の表示は、AIの出力がどのくらい信頼できるかを、ユーザーが判断するのに役立ちます。ただし、確信度はさまざまな方法で示すことができるので、確信度のような統計情報はユーザーにとってわかりづらいことがあります。ユーザーグループが異なると、確信度と確率が意味するところが理解されたりされなかったりするので、プロダクト開発プロセスの早い段階で、さまざまな種類の表示方法をテストするとよいです。
本章の「セクション3」には、確信度の表示とユーザーエクスペリエンスにおけるその役割について、より多くのガイダンスがあります。
例示による説明方法
例示による説明方法は、AIの予測の背景にある理由を説明するのが難しいときに役立ちます。このアプローチは、意思決定にかかわるモデルのトレーニングセットから、ユーザーに例示します。例示は、驚くようなAIの結果をユーザーが理解できるようにしたり、AIがなぜそのように振る舞ったのかを直感的に理解しやすくします。この説明方法は、例示を理解し、AIの分類結果をどれだけ信頼するかを決めるのに、人間の知能に依存します。
特定の出力
ユーザーが「ポイズンオーク」という分類を信頼するかどうかを決められるように、システムはポイズンオークのもっとも類似した画像と、他の葉のもっとも類似した画像を表示します。
システム全体
AIは、エラーを起こしがちな画像の例と、うまく解析される傾向にある画像の例を示します。
インタラクションによる説明方法
AIを説明して、ユーザーが「 メンタルモデル」をつくれるようにするもうひとつの方法は、「どうすれば?」という質問に対して、ユーザーにその場でAIを試せるようにすることです。たとえば、AI音声アシスタントに無理な質問をするように、アルゴリズムがどのように動くのかをテストして、システムの限界を見つけるのです。使いやすさを高め、信頼を築くために、ユーザーが自分の条件でAIに参加できるように、意図的にしてください。
特定の出力
ユーザーは、システムがブッシュの葉の色に過度の重みを与えたため、誤分類につながったのではないかと考えています。
これをテストするために、ユーザーはブッシュの葉がより均一な明るさになるように照明を変更して、分類結果が変わるかどうかを試します。
システム全体
この種の説明方法は、一般的にアプリ全体には使用できません。試すためには、何らかの出力が必要です。
説明をつくるのは困難なので、複数回のユーザーテストが必要になるかもしれないことに注意してください。ユーザーにAIシステムを紹介することについて、詳しくは「メンタルモデル」の章を参照してください。
まったく説明がいらない、あるいは完全な説明が必要になる特殊なケースに注意する
一部のケースでは、ユーザーインターフェイスに何らかの説明を含めても何のメリットもありません。AIの動きが、メンタルモデルに適合し、機能と信頼性に対するユーザーの期待と一致するのであれば、インタラクションで説明することは何もないかもしれません。たとえば、携帯電話のカメラが自動的に明るさを調整する場合、使っている最中に、いつどのようにそれが働くかを説明されても邪魔なだけです。独自の説明方法や、個人データを明らかにするような説明方法も、避けるのが賢明です。ただし、こういった理由から説明を止める前に、部分的説明を使えないかどうか、ユーザーの信頼感への影響はどうか、検討してください。
また別の状況では、完全な説明をすることが理にかなっていることや、法律で義務づけられていることがあります。第三者がその結果を複製することができるほど詳細な説明です。例えば、犯罪者に判決を下すために政府によって使われるソフトウェアでは、システムのあらゆる細部まで完全に開示することを期待するのは理にかなっています。公正で、異議がありえる意思決定をするには、完全な説明責任以上のものは何もないでしょう。完全な説明がいるもうひとつのケースは、AIが、誰もに使われることを意図しているオープンソースソフトウェアの一部であるときです。モデルの完全な説明を求められた場合、モデルのトレーニングに使われた個人データを保護するために、さらに考えるべき点があります。
データ処理とオープンソースAIについての、法的および倫理的問題については「リソース」ページを参照してください。
キーコンセプト
それぞれの重要なインタラクションについて、説明方法が、信頼感をどのように損ね、維持し、高めるかを考えてください。次に、どの状況で説明が必要か、また説明方法の種類を決めます。もっとも良い説明方法は、多くの場合、部分的説明です。
部分的説明をするための選択肢は、たくさんあります。部分的説明は、意図的にシステム機能のうち未知の部分、説明するには複雑すぎる部分、またはたんに役に立たない部分を省略します。部分的説明は、以下のとおりです。
- システム全体。AIシステムのしくみを一般的な用語で説明する。
- 特定の出力。AIが特定の時間に特定の出力をした理由を説明する。
この項の考え方で、ワークシートの演習3をやってみましょう。
➂ ユーザーの意思決定への影響を管理する。
AIにとって、もっともうれしいことのひとつは、人々がより良い意思決定をより頻繁にできるようにすることです。AIと人間の最高のパートナーシップは、それぞれが個々にするよりも、より良い意思決定ができます。たとえば、通勤者は、もっとも良い帰宅ルートを選べるように、交通予測による地域の知識が増えます。医者は患者の病歴についての知識を補うため医学的な診断モデルを使うことができます。このようなコラボレーションを効果的にするには、人々は、システムの予測を信頼するかどうか、いつ信頼するべきかを知る必要があります。
上記のセクション2で説明したように、「モデルの確信度」は、システムの結果の精度がどのくらい確かであるかを示します。モデルの確信度を表示することで、ユーザーは信頼感を調整し、より適切な判断を下すことができます。しかし、それはいつでも実用的とは限りません。このセクションでは、モデルの予測の背景にある確信度をいつどのように表示するかについて説明します。
確信度を見せるべきかどうかを決める
モデルの確信度を直感的にすることは、かんたんではありません。人々が実際の意思決定に使うことができるように、確信度を表示し、それが何を意味するのかを説明する最善の方法については、まだ活発に研究がされています。ユーザーに確信度を正しく解釈できるだけの知識があるとわかっていても、ユーザビリティとシステムの理解を向上させる方法を考えてください。確信度を表示されると、気が散ったり、さらに悪いことには誤解されるリスクがつねにあります。
モデルの確信度を表示することが、ユーザーやプロダクトや機能にとって有益であるかどうか、テストするために多くの時間を取っておくようにしてください。次のようなときは、モデルの確信度を表示しないことを選んだほうがよいかもしれません。
- 確信度が影響を与えない。確信度がユーザーの意思決定に影響を与えないときは、表示しないことを検討してください。直観に反するようですが、きめ細かい確信度を示すことは、その影響が明らかでないときには混乱を招くことがあります。システムの確信度が85.8%と87%だったとき、どうすればよいでしょうか?
- 確信度を表示することが、不信感につながる可能性があるとき。確信度が、あまり精通していないユーザーにとって誤解を招く可能性があるときは、それをどのように表示するか、あるいはまったく表示しないかを、再検討してください。たとえば、誤解を招くほど高い確信度には、ユーザーは盲目的に結果を受け入れる可能性があります。
モデルの確信度をもっともうまく表す方法を決める
調査して、モデルの確信度を表示することで意思決定が良くなると確認できたら、次のステップは適切なビジュアライゼーションを選ぶことです。モデルの確信度を表示する最善の方法を考え出すために、確信度がユーザーにどのようなアクションを求めることになるか考えてください。ビジュアライゼーションの種類は次のとおりです。
分類別
このビジュアライゼーション方法は、確信度を高/中/低などのかたまりに分類し、数値ではなくカテゴリで表示します。考えるべき点は次です。
- チームはカテゴリのしきい値を決めるので、それらの意味と、それがいくつあるべきか、慎重に考えることが重要です。
- それぞれの確信度のカテゴリで、ユーザーが取るべき行動を明確に示します。

モデルの確信度の分類別のビジュアライゼーション
N個の最良(N-Best)の代替
確信度の明示的な指標を表示するのではなく、システムは「N個の最良(N-best)」の代替結果を表示します。たとえば「この写真はニューヨーク、東京、またはロサンゼルスのものである可能性があります」などです。考えるべき点は次です。
- このアプローチは、確信度が低い状況でとくに役立ちます。複数の選択肢を表示すると、ユーザーは自分で判断するようになります。また、システムがさまざまな選択肢をどのように関連づけるのかのメンタルモデルをつくるのに役立ちます。
- 表示する代替選択肢の数を決めるには、ユーザーテストとその繰り返しが必要になります。

モデルの確信度の「N個の最良(N-Best)」ビジュアライゼーション
数値
これの一般的な形式はシンプルなパーセンテージです。数値による確信度の指標は、ユーザーが確率について基本的な理解が十分にあることを前提にしているため、危険です。その他の考えるべき点は次です。
- パーセンテージが何を意味するのか、ユーザーが理解するのに十分なコンテキストを与えてください。初心者ユーザーは、80%という値がそのコンテキストに対して低いのか高いのか、それが自分にとってどんな意味があるのか、知らないときがあります。
- ほとんどのAIモデルは、100%の確信度で予測することはないため、数値モデルの確信度を表示すると、ユーザーはその結果を信じてよいのか混乱することがあります。たとえば、ユーザーが同じ曲を複数回聴いたときでも、システムはそれを100%ではなく97%の一致として表示することがあります。

モデルの確信度の数値によるビジュアライゼーション
データのビジュアライゼーション
これは、確信度の視覚的な表現です。たとえば、財務予測には、システムの確信度にもとづいた代替結果の範囲を示すエラーバーや影つきのエリアが含まれています。ただし、一般的なデータのビジュアライゼーションは、その分野の専門家ユーザーがもっとも理解していることに注意してください。
キーコンセプト
モデルの確信度を示すか示さないかにより、信頼感が高まるかどうか、人々が意思決定をしやすくなるかどうかを、評価するために、ユーザーの多様性を反映している人々にユーザー調査をするとよいでしょう。以下は、尋ねるべき質問のタイプの例です。
- 「この尺度で、あなたがこのレコメンドをどのくらい信用しているか教えてください」
- 「アプリがどのようにしてこのレコメンドに到ったか、質問はありますか?」
- 「何があれば、このレコメンドの信頼感が高まるでしょうか?」
- 「ここに書かれている説明に、あなたはどのくらい満足していますか、それとも不満ですか?」
AIプロダクトや機能にとって、モデルの確信度を表示する必要があることが確認できたら、それを表示する正しい方法を判断するために、テストを繰り返します。
この項の考え方で、ワークシートの演習4をやってみましょう。
まとめ
AIシステムの内部動作の説明をするかどうか、そしてその説明方法は、システムのユーザーエクスペリエンスと意思決定におけるその有用性に大きく影響します。この章で説明した、AIに固有の3つの主な考えるべき点は、次のとおりです。
➀ ユーザーが自分の信頼感を調整できるようにする。システムの目的は、ある状況においてはユーザーに信頼してもらうことですが、ダブルチェックが必要なこともあります。信頼感の調整に影響を与える要因は次のとおりです。
- データソースを明らかにする:AIの予測に何のデータが使われているかをユーザーに知らせることで、プロダクトはコンテクスト上の驚きやプライバシーの疑念を避けることができ、ユーザーはいつ自分で判断するべきかを知ることができます。
- ユーザーのアクションにあわせて説明をする:ユーザーのアクションとシステムの出力とのあいだの明確な因果関係を説明することで、ユーザーは時間とともに正しい信頼感を築いていくことができます。
- 状況による利害の説明:低い確信度で高い利害がある状況では、詳細な説明をし、ユーザーに出力をチェックするように促します。そして、確信度の高い予測の背景にある理論的根拠を明らかにすることで、ユーザーの信頼感を高めることができます。
➁ 理解のために最適化する。ときによっては、明確で包括的な説明をする方法がないかもしれません。システムの開発者にとってさえ、出力の背景にある計算は不可解かもしれません。他のケースでは、予測の背景にある推論を明らかにすることは可能かもしれませんが、ユーザーが理解できるように説明するのは容易でないかもしれません。このようなときは、部分的説明をしてください。
➂ ユーザーの意思決定への影響を管理する。ユーザーがモデルの出力にもとづいて意識決定を下す必要があるとき、モデルの確信度をいつどのように表示するのかが、ユーザーの行動に重要な役割を果たします。モデルの確信度を伝える方法は複数あり、それぞれにトレードオフや考慮事項があります。
議論を円滑にし、イテレーションをスピードアップし、落とし穴を避けたいですか? ワークシートを使用してください。
- Antaki, C. (2007). Explaining and arguing: The social organization of accounts. London: Sage Publications.
- Berkovsky, S., Taib, R., & Conway, D. (2017). How to Recommend? Proceedings of the 22nd International Conference on Intelligent User Interfaces - IUI 17.
- Booth, S. L. (2016). Piggybacking robots: Overtrust in human-robot security dynamics (Unpublished master’s thesis).
- Brandimarte, L., Acquisti, A., & Loewenstein, G. (2012). Misplaced Confidences. Social Psychological and Personality Science,4(3), 340-347.
- Bussone, A., Stumpf, S., & Osullivan, D. (2015). The Role of Explanations on Trust and Reliance in Clinical Decision Support Systems. 2015 International Conference on Healthcare Informatics.
- Cai, C. J., Reif, E., Hegde, N., Hipp. J., Kim, B., Smilkov D., Wattenberg, M., Viegas, F., Corrado, S. G., Stumpe, C.M., Terry, M. Human-Centered Tools for Coping with Imperfect Algorithms during Medical Decision-Making. CHI 2019.
- Cai, C. J., Jongejan, J., Holbrook, J. The Effects of Example-based Explanations in a Machine Learning Interface. IUI 2019.
- Dietvorst, B. J., Simmons, J. P., & Massey, C. (2018). Overcoming Algorithm Aversion: People Will Use Imperfect Algorithms If They Can (Even Slightly) Modify Them. Management Science,64(3), 1155-1170.
- Eslami, M., Karahalios, K., Sandvig, C., Vaccaro, K., Rickman, A., Hamilton, K., & Kirlik, A. (2016). First I “like” it, then I hide it. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems - CHI 16.
- Ehsan, U., Tambwekar, P., Chan, L., Harrison, B., & Riedl, M. O. (2019). Automated rationale generation. Proceedings of the 24th International Conference on Intelligent User Interfaces - IUI 19.
- Fernandes, M., Walls, L., Munson, S., Hullman, J., & Kay, M. (2018). Uncertainty Displays Using Quantile Dotplots or CDFs Improve Transit Decision-Making. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems - CHI 18.
- Harley, A. (2018, June 3). Visibility of System Status
- Hosanagar, K., & Jair, V. (2018, July 25). We Need Transparency in Algorithms, But Too Much Can Backfire
- Kass, A., & Leake, D. (1987). Types of Explanations. Ft. Belvoir: Defense Technical Information Center.
- Kempton, W. (1986). Two Theories of Home Heat Control*. Cognitive Science, 10(1), 75-90.
- Lee, J. D., & See, K. A. (2004). Trust in Automation: Designing for Appropriate Reliance. Human Factors: The Journal of the Human Factors and Ergonomics Society, 46(1), 50-80.
- Lee, S., & Choi, J. (2017). Enhancing user experience with conversational agent for movie recommendation: Effects of self-disclosure and reciprocity. International Journal of Human-Computer Studies, 103, 95-105.
- Logg, J. M., Minson, J. A., & Moore, D. A. (2019). Algorithm appreciation: People prefer algorithmic to human judgment. Organizational Behavior and Human Decision Processes, 151, 90-103.
- Mcnee, S. M., Riedl, J., & Konstan, J. A. (2006). Making recommendations better. CHI 06 Extended Abstracts on Human Factors in Computing Systems - CHI EA 06.
- Miller, T. (2019). Explanation in artificial intelligence: Insights from the social sciences. Artificial Intelligence, 267, 1-38.
- Oxborough, C., Cameron, E., Egglesfield, L., & Birchall, A. (n.d.). Accelerating innovation How to build trust and confidence in AI (Rep.). 2017: PwC.
- Pieters, W. (2010). Explanation and trust: What to tell the user in security and AI? Ethics and Information Technology, 13(1), 53-64.
- Rukzio, E., Hamard, J., Noda, C., & Luca, A. D. (2006). Visualization of uncertainty in context aware mobile applications. Proceedings of the 8th Conference on Human-computer Interaction with Mobile Devices and Services - MobileHCI 06.
- Sewe, A. (2016, May 25). In automaton we trust
- Shapiro, V. (2018, April 12). Explaining System Intelligence
- Wachter, S., Mittelstadt, B., & Russell, C. (2017). Counterfactual Explanations Without Opening the Black Box: Automated Decisions and the GDPR. SSRN Electronic Journal.
- Wang, N., Pynadath, D. V., & Hill, S. G. (2016). Trust calibration within a human-robot team: Comparing automatically generated explanations. 2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI).
- Wilson, J., & Daugherty, P. R. (2018, July). Collaborative Intelligence: Humans and AI Are Joining Forces
- Zetta Venture Partners. (2018, July 28). GDPR panic may spur data and AI innovation