データ収集 + 評価
AIのトレーニングに使うデータの入手と評価には、深く考えるべき点があります。この章の内容は次のとおりです。
- トレーニングデータセットには、AIがユーザーのニーズを確実に満たすだけの特徴量と幅がありますか?
- 既存のトレーニングデータセットを使いますか、独自のトレーニングデータセットをつくりますか?
- ラベルをつけるときに、評価者がデータセットにエラーやバイアスをかけないようにするには、どうすればよいですか?
議論を円滑にし、イテレーションをスピードアップし、落とし穴を避けたいですか? ワークシートを使用してください。
AIを使うときに新しいこと
予測をするためには、AIプロダクトは、データ内のパターンと相関を認識するように、その基礎となる「機械学習」モデルを教える必要があります。これらのデータは「トレーニングデータ」と呼ばれ、画像、ビデオ、テキスト、音声などの集合体になります。既存のデータソースを使ったり、新しいデータを明示的に集めて、システムをトレーニングすることができます。たとえば、動物保護センターの犬の画像のデータベースを使用して、一般的な犬種を認識するように、機械学習モデルをトレーニングすることができます。
入手や収集したトレーニングデータ、そしてそのデータの「ラベルづけ」によって、システムの出力が直接に決まります。つまり、ユーザーエクスペリエンスの質が決まるということです。AIを使うことがプロダクトにとって正しい道であると確信したら(「ユーザーニーズ + 成功の定義」を参照)、以下を検討してください。
➀ ユーザーのニーズをデータのニーズに変換する。モデルのトレーニングに必要なデータの種類を決めます。「予測検出力」、関連性、公平性、プライバシー、およびセキュリティを考慮する必要があります。
➁ 責任を持ってデータを入手する。すでにラベルづけされたデータを使用するときも、自分で収集するときも、データが自分のプロジェクトに適しているかどうか、データとその収集方法を評価することが重要です。
➂ 評価者とラベリングの設計をする。「教師あり学習」では、正確なデータラベルをつけることが、モデルから意味のある出力を得るために、重要です。評価者への指示とUIフローを慎重に設計することで、ラベルの品質が良くなり、出力が向上します。
➃ モデルをチューニングする。モデルが実行されたら、機械学習の出力を解釈して、プロダクトの目標とユーザーのニーズに合うようにします。合っていない場合は、トラブルシューティングをします。データに潜在的な問題がないかを調べます。
➀ ユーザーのニーズをデータのニーズに変換する
AIモデルをトレーニングするために使うデータセットには、1つ以上の「特徴量」を含む「サンプル」と、場合によって「ラベル」が含まれます。
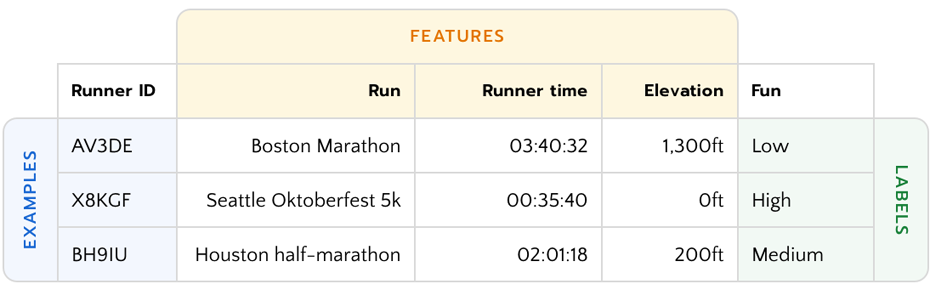
特徴量の範囲、ラベルの品質、およびトレーニングデータセットのサンプルの代表性は、すべてAIシステムの品質に影響を与える要因です。
上の表には、マラソンのレースがどのくらい楽しいかを予測する機械学習モデルを、トレーニングするためのデータが含まれています。サンプル、特徴量、ラベルが、そのモデルの品質に、どのように影響を与えるかを、次に示します。
サンプル
ランニングをレコメンドするアルゴリズムのトレーニングに使われたサンプルが、優れたランナーからのものだけであったら、より広いユーザー層の予測をするためのモデルは、おそらくできないでしょう。しかし、優れたランナー向けのモデルをつくるためならば、役立つでしょう。
特徴量
標高変化の特徴量がデータセットになければ、機械学習モデルは、3.0マイルの上り坂の走行と、3.0マイルの下り坂の走行を、同じに扱いますが、それは人間の体感とは大きく異なります。
ラベル
ランナーの主観的な体験を明らかにするラベルは、システムが楽しいランニングになる可能性がもっとも高い特徴量を判断するために、不可欠です。
機械学習モデルのトレーニングに必要なサンプル、特徴量、ラベルを決めるには、以下の例に示すように、コンセプトの段階で、データのニーズを検討してください。
この例では、「忙しいスケジュールに合わせて走りたい」というユーザーのニーズを解決するプロダクトの、データのニーズの内訳を示しています。
ユーザーのニーズとデータのニーズを一致させる
- ユーザー:ランナー
- ユーザーのニーズ:もっと頻繁に走る
- ユーザーのアクション:走り終えたとき、またはアプリの使用中
- 機械学習システムの出力:どの走行ルートをレコメンドするか、いつレコメンドするか
- 機械学習システムの学習:走る動作を検知したとき、走り終えたとき、走り続けているときの行動パターン
- 必要なデータセット:アプリからの走行データ、人口統計データ、生理的データ、ローカルの地理データ
- データセットに必要な主な特徴量:ランナーの人口統計、時刻、完走率、ペース、走行距離、標高変化、心拍数
- データセットに必要な主なラベル:ランナーがアプリのレコメンドを受け入れたか却下したか、レコメンドを却下した理由と、レコメンドされたランニングの楽しさについての、ユーザーからのフィードバック
機械学習モデルの基本については、「リソース」で詳しく学ぶことができます。必要なデータの種類を把握したら、「Google AI原則」と「責任あるAIの実践」をフレームワークとして使用して、次に示す重要な点を考えます。
プライバシーとセキュリティを管理する
他のプロダクトと同じように、ユーザーのプライバシーとセキュリティを保護することが不可欠です。上記のランニングの例でも、このモデルをトレーニングするために必要な生理的データおよび人口統計データは、機微な情報とみなすことができます。
先に進む前に、チームは、ユーザーのプライバシーとセキュリティを保護しなつつ、データを安全に収集して使うことができるかどうかを、検討する必要があります。AIと機械学習の固有の性質をふまえた重要な質問があります。以下に、そのような質問が2つあります。チームのなかで、プライバシーとセキュリティの専門家と、こういったことについて話し合ってください。
データの使用におけるユーザーの同意事項には、どのような制限がありますか?
データを収集する際、ベストプラクティスは、そして多くの国での法律でも、システムが使うデータとその使用方法を、できるだけユーザーがコントロールできるようにすることです。また、ユーザーが、自分のアカウントをオプトアウトや削除できる機能をつける必要があります。システムがそれに対応するようにしてください。
ユーザーのデータを誤って漏洩する危険はあるでしょうか? その結果はどうなりますか?
たとえば、個人の健康データは非公開で安全に管理されていても、AIアシスタントがユーザーに自宅のスマートスピーカーで薬を服用するように通知した場合、個人の医療データを室内にいる他の誰かに聞かれる可能性があります。
未学習と過学習のバランスをとる
単一のコンテキストで機能するようにプロダクトをつくるには、そのコンテキストを確実に反映するデータセットを使います。たとえば、発話を目的とした自然言語理解モデルの場合、ユーザーが検索エンジンに入力した単語はトレーニングデータに適しません。話すのと同じように検索語句を入力することは、ないからです。
トレーニングデータがコンテキストに適合していないときは、トレーニングセットに「過学習」したり「未学習」したりするリスクも高くなります。過学習とは、機械学習モデルがトレーニングデータに合わせて調整されすぎていることを意味し、さまざまな原因で起こります。機械学習モデルがトレーニングデータに過学習しているとき、トレーニングデータにおいては優れた予測ができますが、テストセットや新しいデータが与えられたときには、成績が悪くなります。
未学習による予測不良もあります。モデルが、トレーニングデータセットの特徴量の関係の複雑さをうまくとらえることができないとき、トレーニングデータや新しいデータに適切な予測をすることができません。
過学習や未学習を避けるための、機械学習モデルのトレーニングの微妙なニュアンスを理解するうえで、チームのソフトウェアエンジニアや研究者の参考になる「リソース」はたくさんあります。しかしまずは、良いトレーニングセットに必要と思われるサンプル、特徴量、ラベルについてコンセプトを議論する場に、プロダクトチームの全員を参加させましょう。そして、ユーザーのニーズにもとづいて、どの特徴量がもっとも重要か、議論します。
公平性を守る
開発のあらゆる段階で、人間のバイアスは、機械学習モデルに入り込んできます。データは現実の世界で人間から収集され、その人々の個人的な体験とバイアスを反映しています。そしてこれらのパターンは、機械学習モデルによって、暗黙のうちにとらえられ増幅されます。
このガイドブックは、機械学習の公平性についていくつかのアドバイスを載せていますが、そのトピックについての徹底的なリソースではありません。AIの公平性に取り組み、不公平なバイアスを最小限にすることは、活発な研究分野です。機械学習の公平性についての最新のガイダンスと推奨されるプラクティスについては、Googleの「責任あるAIの実践」をご覧ください。
機械学習システムが、ユーザーを失敗させる例をいくつか挙げます。
- 象徴型の危険性。システムが特定のグループについての否定的な固定観念を増幅したり反映したとき。
- 機会の拒否。現実の生活と、個人の機会、リソース、生活全体の質に、永続的な影響を与える予測と決定をシステムがするとき。
- プロダクトの不均衡な失敗。プロダクトが機能しない、または、特定のユーザーグループに頻繁に歪んだ出力がされるとき。
- 不利益による損害。システムが、特定の人口統計的な特性と、ユーザーの行動や興味とのあいだに、不利な関連性を推論するとき。
公平性の標準的な定義はなく、モデルの公平性は状況に応じて変わります。しかし、データセットに含まれる問題のあるバイアスを抑えるために、できる手順はあります。
ユーザーのさまざまなグループに適用できるデータを使用する
トレーニングデータは、それを使う人々の多様性と文化的背景を反映するべきです。「Facets」などのツールを使ってデータセットを調べ、そのバイアスをより深く理解してください。その際、モデルを適切にトレーニングするには、実世界では同じ割合で存在しない可能性があるさまざまなユーザーグループから、同じ割合でデータを収集する必要があることに注意してください。たとえば、音声認識ソフトウェアを米国内のすべてのユーザーで同じように機能させるには、英語以外の話者のデータが50%、それがたとえ少数派であっても、トレーニングデータセットに含まれている必要があります。
データ収集と評価プロセスにおけるバイアスを考慮する
真に中立的なデータというものはありません。単なる写真でも、撮影に使われる機器と照明で、写りが変わります。さらに、人間がデータの収集と評価に関わっているので、他のあらゆる人間の活動と同じように、その成果には人間のバイアスが含まれます。下記の「ラベリング」のセクションに詳しくあります。
たとえば、新しい健康とフィットネスの目標を、ユーザーにレコメンドするシステムをつくっているとします。フィットネスの習熟度が高い人から低い人までいるユーザー層が、確実に達成できるゴールを設定することを目的としているとき、トレーニングデータセットには、若く健康的な人々だけでなく、さまざまなタイプのユーザーのデータを含めることが重要です。
公平性のトピックの詳細については、Googleの機械学習の公平性の「概要」および「短期集中コース」を参照してください。
キーコンセプト
チームがプロダクトが必要とするデータについて高度な理解をし、特定のユーザーニーズとそれをつくるのに必要なデータを自分たちで変換するようにします。
このステップでは、できるだけ具体的にするようにしてください。これは、チームがこれからリソースを遣うことに決めたユーザーエクスペリエンスに、直接に影響します。
この項の考え方で、ワークシートの演習1をやってみましょう。
➁ 責任を持ってデータを入手する
必要なトレーニングデータの種類がわかったら、どこで、どのようにしてデータを得るか、検討します。既存のデータセットを使うこと、独自のデータを収集すること、またはそのふたつを組み合わせることがあります。どの方法をとるにしても、データとインフラストラクチャを安全に使えるように、許可を得てください。
既存のデータセットを使う
データセットを一から構築するのは不可能なときもあるでしょう。代わりに、Google Cloud AutoML, Google Dataset Search, Google AI datasets, Kaggle などの情報元から、既存のデータを使うことができます。「教師あり学習」をする場合、このデータはラベルづけされていることもあれば、ラベルを自分で追加する必要があることもあるでしょう(下記の「ラベリング」を参照)。データセットの利用規約を必ず確認し、それがあなたのユースケースに適しているかどうかを確かめてください。
既存のデータセットを使う前に、「Facets」などのツールで徹底的に調べて、ギャップやバイアスをよく理解してください。実際のデータは乱雑なことが多いので、かなりの時間をかけてデータをきれいにする必要があるでしょう。このプロセスで、値の欠落、つづりの間違い、フォーマットの誤りなどの問題が見つかることがあります。データ前処理テクニックについては、「データ前処理」についての開発者向けガイドラインをご覧ください。これらのガイドラインは、目指すユーザーエクスペリエンスに、データが役立つようにしてくれるでしょう。
自作のデータセットをつくる
独自のデータセットをつくるときは、まず、プロダクトが対象としている分野の専門家を観察することです。たとえば、会計担当者が財務データを分析したり、植物学者が植物を分類したりするのを観察しましょう。彼らが、機械学習を使わないで、問題の解決策を考えたり作業したりするさまをインタビューをすれば、意思決定をするときや行動を起こす前に、彼らがどのデータを見ているかという洞察を得ることができるでしょう。
また、関連性があると思われる利用可能なデータセットを調査し、使えるところがないかどうか、評価する必要があります。モデルが十分な学習をするためには、複数のソースからデータを組み合わせる必要があるかもしれません。
データセットに使えるかもしれないソースを集めたら、しばらく時間をかけて、データを把握してください。次の手順を踏みましょう。
- データソースを特定します。
- データソースが更新される頻度を確認します。
- 特徴量の取り得る値、単位、データ型を調べます。
- 異常値を見つけ、それらが本当の異常値なのか、それともデータの誤りによるのかを調べます。
データセットがどこから来たのか、それがどのように集められたのか、理解することは、潜在的な問題を発見するのに役立ちます。以下は、注意が必要なデータセットのよくある問題です。
フォーマットを検討する
現実のデータは実に乱雑です。「ゼロ」という値は、実際に「0」が測定されたのでしょうか、あるいは測定値そのものがないことを示しているのでしょうか。「国」という特徴量には「US」「USA」「United States」など、さまざまな形式の登録データが含まれているかもしれません。
人間ならば、データを見るだけで意味を見つけることができますが、機械学習モデルは一貫したフォーマットのデータでなければ、うまく学習することができません。
他の機械学習モデルからのエラーの混入を避ける
モデルをトレーニングするための入力となる特徴量として、他の機械学習システムの出力を使用している場合は、これが危険なデータソースであることに注意してください。この特徴量についてのエラーは、システムの全体にかかわるエラーを複雑にします。元のトレーニングデータから離れているほど、エラーの原因を特定するのが難しくなります。
エラーの原因を特定する方法については、「エラー + 上手な失敗」の章を参照してください。
個人を特定できる情報を保護する
どんなデータを使用していても、個人を特定できる情報が含まれている可能性があります。データを匿名化するためのアプローチには、データ集約と墨消しがあります。ただし、これらの方法でも、あらゆる状況でデータを完全に匿名化できるわけではないため、専門家に相談してください。
「データ集約」は、一意の値を集計値に置き換えるプロセスです。たとえば、ユーザーの日々の1分あたりの最大心拍数のリストを、集計値(1分あたりの平均心拍数や、高/中/低のようなカテゴリのラベル)に置き換えることができます。
「墨消し」は、いくつかのデータを削除して、完成度の低い状態にします。そのような匿名化のアプローチは、単一のユーザを特定するための特徴量の数を減らすことを目的としています。
データを分割する
そして最後に、データを「トレーニングセット」と「テストセット」に分割する必要があります。モデルはトレーニングデータで学習し、テストデータで評価されます。テストセットは、モデルがこれまで学習したことのないデータです。モデルがうまく機能するか、どの程度うまく機能するかを判断するためのものです。分割は、データセット内のサンプルの数やデータの分布などの要因によって異なります。
トレーニングセットは、モデルが正しく学習するために十分な大きさである必要があります。また、テストセットは、モデルのパフォーマンスを適切に評価できる大きさである必要があります。通常は、開発者は十分なデータがモデルの成功を左右すると気づいています。そのため、もっとも効率的な分割比率がいくつかを判断するために、時間をかけてください。データセットの一般的な分割比率は、トレーニング用に60%、テスト用に40%になります。詳細は「リソース」を参照してください。
ユーザーから生きたデータを集める
モデルがトレーニングされ、プロダクトが現実の世界で使われるようになると、プロダクトからのデータ収集をすることができるようになり、継続的に機械学習モデルを改善することができます。このデータを、どのように収集するかは、その品質に直接に影響します。データは、アプリ内のユーザーの行動の背後で「暗黙的に」収集することもできますし、ユーザーに直接に質問することで「明示的に」収集することもできます。それぞれ設計する上で考慮すべき点が異なります。「フィードバック + コントロール」の章で詳しく説明しています。
キーコンセプト
機械学習の組み込まれたプロダクトは、機能するために大量のデータを必要とします。これは、プロダクトチームがつまづきやすいところです。機械学習モデルのトレーニングとテストの両方に十分なデータを用意することは、プロダクトが機能するために不可欠です。以下の質問が重要です。
- 新しいデータセットをつくる必要がある場合、データをどのように収集する予定ですか?
- 既存のデータセットを使う場合、ユーザー層にあわせて何か変更や追加をする必要はありますか?
この項の考え方で、ワークシートの演習2をやってみましょう。
➂ 評価者とラベリングの設計をする
「教師あり学習」では、正確なデータラベルは、その機械学習の出力を決める重要な要素です。ラベルは、自動化されたプロセスや、「評価者」と呼ばれる人々により、つけることができます。「評価者」とは、さまざまな文脈、スキルセット、専門性のレベルの総称です。評価者は次のようになります。
- あなたのユーザー:たとえば、写真のタグづけなどのアクションを通じて、プロダクト内に「生成された」ラベルを生み出す。
- ジェネラリスト:クラウドソーシングのツールを介して、さまざまなデータにラベルづけをする。
- そのテーマについて訓練された専門家:医療用画像のようなものにラベルをつけるための特殊なツールを使う。
評価者が、ラベルづけの目的と、その理由を理解し、ラベルづけを効率的にできるツールがあれば、より正しくラベルをつけることができるでしょう。
ラベルを設計するときに、主に考えるべき点は次です。
評価者の集団の多様性を確保する
評価者の集団における、視点と潜在的なバイアスについて考えてください。多様性を確保するにはどうすればいいでしょうか。それらの観点がラベルの品質にどのように影響を与えるでしょうか。状況によって、無意識のバイアスに気がついてもらうよう、評価者をトレーニングをすることも効果的です。
評価者の背景とインセンティブを調査する
評価者の体験と、この作業をしている方法と理由を考えてみてください。退屈、繰り返し、インセンティブの設計の悪さなどが原因で、作業が正しくなされないリスクがつねにあります。
評価者ツールを評価する
ラベリングのためのツールは、プロダクト内での入力から専用のソフトウェアまで、さまざまです。プロダクト内でラベルをつけさせるときは、ユーザーが正しい情報をかんたんに入力できるようにUIを設計してください。専門的な評価者のツールをつくるには、記事「First: Raters」が、以下のような推奨事項を載せています。
- キー操作をしやすくするために、複数のショートカットを用意する。評価者が素早く動き、効率を維持できるようになります。
- ラベルに手軽にアクセスできるようにする。すべてのラベルは、評価者がする各作業において、目に見える状態にしておき、そして利用可能な状態にしておきます。UIで、ラベルを適用することは、速くてかんたんにします。
- 評価者の意識を変える。ラベルづけは複雑になることがあります。評価者がセカンドオピニオンを求め、エラーを修正できるように、柔軟なワークフローと、編集や順序外の変更へのサポートをします。
- エラーを自動検出して表示する。チェックやフラグ立てによる不測のエラーをかんたんに回避できます。
評価者からデータを収集したら、「検者間信頼性」を分析するために、統計的なテストをする必要があります。信頼性の欠如は、指示をうまく設計できていない、というサインかもしれません。

キーコンセプト
評価者のためのツールを設計する前に、エンドユーザーについて考えるのと同じように、評価者のニーズを調査してください。評価者が作業をうまく進めるモチベーションと能力は、今後に組み立てるすべてのことに、直接に影響を与えます。
- 評価者は誰ですか?
- 評価者の背景とインセンティブは何ですか?
- 評価者はどんなツールを使っていますか?
この項の考え方で、ワークシートの演習3をやってみましょう。
➃ モデルをチューニングする
モデルをトレーニングデータでトレーニングしたら、定義しておいた成功指標にしたがって、ターゲットユーザーのニーズに対応できているかどうか、出力を評価します。もし対応できていない場合は、それに応じて「チューニング」をする必要があります。「チューニング」とは、「トレーニングプロセスのハイパーパラメータ」や、モデルのパラメータや、報酬関数を調整したり、トレーニングデータをトラブルシューティングしたりすることを意味します。
モデルを評価するには、次のようにします。
- 「What If ツール」などのツールを使って、モデルを調べ、盲点を見つけます。
- テスト、テスト、継続的なテスト。
- 開発の初期段階では、ターゲットオーディエンスのさまざまなユーザーから、定性的なフィードバックを細かく得て、トレーニングデータセットやモデルのチューニングにおける「赤信号」の問題を見つけます。
- テストの一環として、ユーザーからのフィードバックを得るため方法が、適切で深く考えられたメカニズムになっていることを確認してください。詳しくは「フィードバック + コントロール」の章を参照してください。
- システムのユーザーエクスペリエンスを監視するために、カスタムダッシュボードとデータビジュアライゼーションを構築する必要があるかもしれません。
- 報酬関数を決定するときには、予想だにしなかった二次効果がないか、とくに注意してチェックしてください。詳しくは「ユーザーニーズ + 成功の定義」の章で述べています。
- モデルの変更を、主観的なユーザーエクスペリエンスをあらわす明確な指標に、結びつけるようにしてください。たとえば、顧客満足度や、モデルのレコメンドをユーザーが受け入れた頻度などです。
修正すべき問題を見つけたら、それらを特定のデータの特徴量やラベル(またはその欠如)、またはモデルパラメータに、対応づけする必要があります。これはかんたんでも直接的でもないかもしれません。問題を解決するには、トレーニングデータの「分布」を調整する、ラベリングの問題を修正する、より関連性のあるデータを収集するなどの手段が必要になることがあります。以下は、チームがチューニングに取り組んだ例です。
ランニングアプリが、消費カロリーを計算し、ユーザーが目標カロリー数を燃やせるように、ランニングの途中で変更することをレコメンドする新機能を発表したとしましょう。
ベータテスト中に、これらのレコメンドを受け取ったユーザーは、他のユーザーよりもランニングを途中でやめる可能性がはるかに高いことがわかりました。さらに、レコメンドに従ってランニングを完了したユーザーは、同じ週に2回目のランニングをする可能性が低いこともわかりました。プロダクトマネージャは、もともとこの機能は失敗だと思っていたものの、ユーザーへのインタビューやデータを詳細に調査したところ、アルゴリズムが推定カロリー消費量を計算するときに、外気温やユーザーの体重のような重要なデータを、適切に重みづけしていませんでした。
ユーザー調査により、カロリー計算が信頼できず、ランニングの途中変更をするというレコメンドを受け入れる意味がわからなかったために、一部のユーザーがやめてしまったことが明らかになりました。
エンジニアリングチームはアルゴリズムを再調整し、正しい機能をリリースすることができました。
キーコンセプト
チューニングは、ユーザーのフィードバックや、予期しない状況で発生する問題に対応するために、機械学習モデルを調整していく継続的なプロセスです。チューニングは終わることがありませんが、開発の初期段階ではとくに重要です。
- モデルを早期にテストする計画を立てていますか?
- 初期のベータユーザー群は、モデルを正しくテストするのに十分な多様性がありますか?
- チューニングが成功したかどうかを判断するためにどのような指標を使用しますか?
「What-if ツール」を使って、このセクションのチューニングについての考え方を実践してください。ユーザーのフィードバックに応じてモデルを調整する方法については「フィードバック + コントロール」の章を参照してください。
まとめ
データはあらゆる機械学習システムの土台です。関連するコンテキストから責任を持ってデータを入手し、問題のあるバイアスをチェックすることは、より良いシステムをつくるのにつながり、そしてユーザーのニーズにより効果的に対応できるようになります。データ収集と評価について、主に考えるべき点は次です。
➀ ユーザーのニーズをデータのニーズに変換する。効果的なAIモデルをトレーニングするために必要な特徴量、ラベル、およびサンプルについて、組織横断型のチームで慎重に検討してください。ユーザーのニーズ、ユーザーの行動、機械学習の予測を、必要なデータセットへと落とし込むために、体系的に作業してください。必要になるデータセットを探したり、それを収集する計画を立てるときは、データの検査、潜在的なバイアスの原因の特定、データ収集方法の設計に、細心の注意を払う必要があります。
➁ 責任を持ってデータを入手する。データ調達の一環として、関連性、公平性、プライバシー、およびセキュリティを考慮する必要があります。詳細は「Google AI原則」と「責任あるAIの実践」を参照してください。これらは、既存のデータセットを使うか、新しいトレーニングデータセットをつくるかにかかわらず、適用されます。
➂ 評価者とラベリングの設計をする。正しくラベルづけされたデータは、より良い教師あり機械学習システムにとって、非常に重要な要素です。評価者とその使うツールを慎重に検討することで、ラベルがより正確になるでしょう。
➃ モデルをチューニングする。モデルをつくったら、それを厳密にテストして、チューニングする必要があります。チューニングをする段階では、モデルのパラメータを調整するだけでなく、データも検査します。多くの場合、出力エラーは、データの問題に起因します。
議論を円滑にし、イテレーションをスピードアップし、落とし穴を避けたいですか? ワークシートを使用してください。
- Alexsoft. (2018, March 29). How to Organize Data Labeling for Machine Learning: Approaches and Tools.
- Alexsoft. (2017, June 16). Preparing Your Dataset for Machine Learning: 8 Basic Techniques That Make Your Data Better
- Amazon Machine Learning Developer Guide. (2019). Amazon Web Services.
- G, Y. (2017, August 31). The 7 Steps of Machine Learning.
- Giffin, D., Levy, A., Stefan, D., Terei, D., Mazières, D., Mitchell, J., & Russo, A. (2017). Hails: Protecting data privacy in untrusted web applications. Journal of Computer Security, 25(4-5), 427-461.
- Korolov, M. (2018, February 13). AI’s biggest risk factor: Data gone wrong.
- Mitchell, M., Wu, S., Zaldivar, A., Barnes, P., Vasserman, L., Hutchinson, B., … Gebru, T. (2019). Model Cards for Model Reporting. Proceedings of the Conference on Fairness, Accountability, and Transparency - FAT* 19.
- Rolfe, R., & May, S. (2018, June 22). First: Raters Designing for AI’s unseen users can lead to better products in the long run.
- Seif, G. (2018, July 6). How to collect your deep learning dataset
- Shapiro, D. (2017, November 6). Artificial Intelligence and Bad Data
- Shapiro, D. (2017, September 19). Artificial Intelligence: Get your users to label your data
- Smith, D. (2019, January 29). What is AI Training Data?
- Smith, D. (2018, July 5). Netflix and Chill: Building a Recommendation System in Excel Learn the Machine Learning “Magic” behind the Binge
- Teltzrow, M., & Kobsa, A. (2004). Impacts of User Privacy Preferences on Personalized Systems. Designing Personalized User Experiences in ECommerce Human-Computer Interaction Series, pp.315-332.
- Yang, Q., Scuito, A., Zimmerman, J., Forlizzi, J., & Steinfeld, A. (2018). Investigating How Experienced UX Designers Effectively Work with Machine Learning. Proceedings of the 2018 on Designing Interactive Systems Conference 2018 - DIS 18.